Adwindが持つ難読化された文字列の解読(2016-04-25)
2015年後半から2016年にかけて、Adwindと呼ばれる遠隔操作マルウエアを用いた攻撃が世界的に増えました[1]。JPCERT/CCにおいても、このマルウエアが添付されたメールを受信したとのインシデント報告を受けました。
Adwindは、Javaで作られたマルウエアであり、Windows以外のOS上でも動作します。任意のファイルをダウンロードし実行する機能や、感染したマシンの情報をC&Cサーバへ送信する機能を持つ他、プラグインによる機能拡張も可能です。
Adwindの特徴の一つは頻繁に繰り返されるバージョンアップです。わずか2週間の間隔で新しいバージョンが投入されたケースさえありました。Adwindが関連するインシデントの調査においては、使われたバージョンのAdwindの機能を正確に把握しておくことが重要です。
ところが、Adwind本体に内蔵されている約500個の文字列には巧妙な難読化処理が施されており、Adwindの機能を分析するには、それらの文字列を平文に戻す処理が必要です。JPCERT/CCでは、Adwindが持つ難読化された文字列の解読を効率的に行うためのツール「adwind_string_decoder.py」を作成しました。今回は、このツールについて紹介します。
なお、Adwindには幾つかの世代[1]がありますが、本解説および作成したツールが対象としているのは、2015年後半以降の攻撃に使用されている新しいAdwindです。
難読化された文字列
Adwindが持つ多くの文字列は、図 1のように難読化されています。その数はAdwindのバージョンによって異なりますが、概ね500個あります。これらの難読化された文字列は、Adwindのバージョンが異なると、全く違っています。
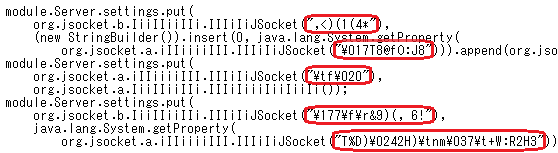
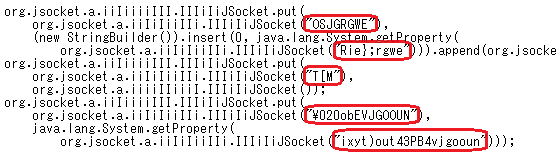
図 2は、図 1と同じ処理を行っている箇所です。いずれの図も、Adwindを逆コンパイルしたコードに、読みやすくするための改行やインデントを入れてあります。図 2は2015年8月の中旬、図 1は2015年11月の下旬にみられたバージョンです。前述のようにAdwindは頻繁にバージョンアップされており、しかも、バージョンごとに異なった鍵による難読化が施されています。
図1および図2に示した箇所は、C&Cサーバへ送信される情報を収集する処理の一部であり、感染ユーザ名を取得する処理を含んでいます。しかし、情報を取得する処理の呼出し時に、取得すべき情報が「ユーザ名」であることを、難読化した文字列で指定しているので、文字列の難読化を解除して平文に戻さない限り、感染ユーザ名を取得していることがコードからは分かりません。さらに、文字列を難読化する鍵が、後述のとおり、分散かつAdwindのバージョンによって異なっているため、難読化を解除することが容易ではありません。
インシデント対応のための分析では、C&Cサーバへ送信される情報を特定することによって、感染被害や、感染後の次の攻撃が推察できる場合があり、どのような情報を収集してC&Cサーバへ送信する機能を持っているかを詳しく分析することが重要です。そのための静的なコード解析を効率的に行うためには、様々なバージョンのAdwindに対して、概ね500個もある難読化された文字列を素早くデコードできる必要があります。
文字列デコード処理の分析
一般にストリーム暗号では、任意の長さのデータmを暗号化する場合、mと同じ長さの疑似乱数列kを暗号鍵から生成し、mとkとの排他的論理和m XOR kにより暗号文を生成します。そして、暗号文m XOR kと疑似乱数kとの排他的論理和をとること((m XOR k) XOR k)により、復号が行われて平文mを得ます。
Adwindで行われている文字列の難読化は、上述のストリーム暗号と似た方法により行われていますが、Adwindの場合にはkは暗号鍵から生成するのではなく、次に述べるような方法で作られます。なお、本報告ではAdwindにおけるkを「難読化する鍵」ないし「難読化鍵」と呼んでいます。
Adwindのコード中には、難読化された文字列を引数とし、デコードした文字列を返す関数が複数存在しています。以下、それらの関数をFiと書くことにします。ここで注意すべきは、Fiは同じ入力に対しても、呼出し元メソッドが異なると、それに応じて異なる同じ結果を返すような関数として作られていることです。これは、Adwindを静的分析する者が、文字列に対応する難読化鍵を得るためには、当該文字列がどのFiによって処理されるかとともに、当該文字列がどのメソッド中に存在してFiを呼出しているのかについても調べておく必要があることを意味しています。Fiがどのような難読化鍵を生成して難読化の解除処理をしているかを次に述べます。
Fiは、Fiの呼出し元のメソッド名とクラス名の2つの文字列を素材として、それらに次の要素から決まる変換処理を施したものを、鍵として必要な長さまで反復することにより、難読化鍵を生成しています。
- 要素1: メソッド名とクラス名の文字列を並べて結合する時、どちらを先にするか
- 要素2: 素材とした文字列を全く異なる文字列に変換するための演算に使われる数値
どのFiもほとんど同じコードにより実現されていますが、上記の2つの要素に相当するコードだけがFiごとに異なっています。また、要素2は、直接の定数としてコード中に存在せず、演算を含む難読化された処理を経て算出される仕組みになっています。
Adwindは、5種類以上のFiと、難読化された文字列を含むメソッドを60個程度もっており、それらの実際の組合せとして概ね100個の難読化鍵が使われていることになるため、Fiが比較的単純なコードで実現されている割には、難読化の解除を大変に難しいものにしています。
また、上記の2つの要素はAdwindのバージョンによっても異なっています。このため、特定のバージョンのAdwindのデコード処理を再現するツールを作成したとしても、他のバージョンのAdwindの分析には使えません。
一方、 Fiには共通して次の特徴があります。
- Stringオブジェクトの引数を1つもつ
- デコード後の文字列をStringオブジェクトで返すstatic関数である
- 呼出し元の情報を得るための決まったAPI呼出しを含む
- 関数内に登場する命令の種類が少ない
これらの特徴を利用し、できるだけAdwindのバージョンに依存しない方法で、難読化された文字列を自動的にデコードするツール「adwind_string_decoder.py」を作成しました。
adwind_string_decoder.py
このツールはGitHub上で公開していますので、ダウンロードしてご使用ください。
JPCERTCC/aa-tools - adwind_string_decoder.py
https://github.com/JPCERTCC/aa-tools
なお、adwind_string_decoder.pyを使用するためには、JDK(Java Development Kit)に含まれている逆アセンブラjavapが必要です。javapへパスを通しておくか、もしくは環境変数JAVA_HOMEがJDKフォルダを指すように設定しておく必要があります。
adwind_string_decoder.pyは概ね次の手順で処理を行います。
- 指定されたjarファイルを展開し、逆アセンブラを呼び出す
- 逆アセンブルされた全てのコードを走査し、引数や型などから、デコード処理らしき関数を抽出する
- その関数内に登場する命令の種類や流れからデコード処理かどうかを判定する
- デコード処理ならば、難読化鍵生成の要素1と2を求める
- 再び全てのコードを走査し、デコード処理を呼び出している箇所を抽出する
- それぞれのメソッド名とクラス名を求め、難読化鍵の素材とする
- それぞれの難読化鍵を生成し、文字列をデコードする
adwind_string_decoder.pyを使用する前に - Adwindのアンパック
典型的にAdwindはパックされており、検体のjarファイルの中に、本体となるjarファイルが隠されています。Adwindをアンパックする機能はadwind_string_decoder.pyには持たせていませんので、予め分析環境でAdwindの検体を動作させ、メモリ上に出現したjarイメージを取り出します。そのjarイメージはメモリ上から消滅しやすいのですが、jdbなどのJavaデバッガを用いて、jarファイルを読み込むAPIにブレークポイントを仕掛けておくと取り出しやすくなる場合があります。
adwind_string_decoder.pyの実行
難読化された文字列をデコードするには、アンパックしたjarファイルと、出力ファイルを指定し、次のように実行します。
python adwind_string_decoder.py sample.jar output.jasm
すると、図 3のようにデコードした文字列をコメントとして挿入した逆アセンブリコードが出力されます。
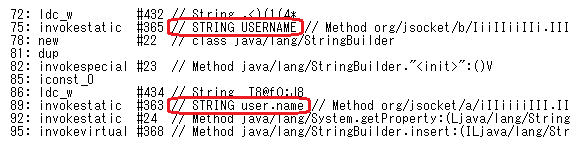
また、次のように出力ファイルを指定せずに実行すると、逆アセンブリコードの出力は抑止され、デコードした文字列のみを標準出力へ図 4のように出力することができます。
python adwind_string_decoder.py sample.jar

また、逆コンパイラで出力したJavaコードを走査し、デコード処理への関数呼出しと引数を、デコード後の文字列で置換することもできます。ただし、完全修飾名(FQN)形式のコードのみに対応しています。例えば、図 5のようなコードから、図 6のような出力を得ることができます。逆コンパイル機能はadwind_string_decoder.pyには持たせていませんので、予め逆コンパイラで出力したファイルを格納したフォルダと、デコード後のファイルを出力するための新しいフォルダ名を指定し、次のように実行します。
python adwind_string_decoder.py sample.jar source_folder output_folder
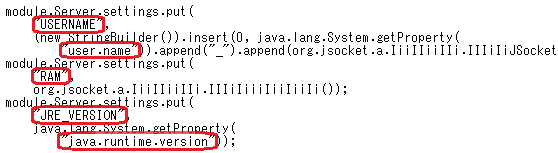
こうして文字列がデコードされたコードからは、C&Cサーバへ送信される情報として何が収集されるのかを容易に読み取ることができます。また、どのOSに感染することができるのか、それぞれのOS上でのAdwindの機能に違いはあるのか、なども読み解くことができます。
おわりに
2016年2月上旬から、この新しいAdwindを用いた攻撃はみられなくなってきました。ようやく沈静化したのかもしれませんが、2016年2月末においても新たに検体はみつかっているようです。もし新しいバージョンのAdwindがみられた際は、今回紹介した手法やツールをご活用いただければ幸いです。
分析センター 今松 憲一
参考情報
[1]Adwind: FAQ - Securelist
https://securelist.com/blog/research/73660/adwind-faq/
Appendix 検体のSHA-256ハッシュ値
- 033db051fc98b61dab4a290a5d802abe72930338c4a0dd4705c74eacd84578d3
- f8f99b405c932adb0f8eb147233bfef1cf3547988be4d27efd1d6b05a8817d46
